大数据培训_Kafka 组件的介绍
Kafka定义Kafka 是一个高吞吐、分布式、基于发布订阅的消息系统,利用Kafka技术可在廉价PC Server上搭建起大规模消息系统。
Kafka应用场景简介Kafka和其他组件比较,具有消息持久化、高吞吐、实时等特性,适用于离线和实时的消息消费,如网站活性跟踪、聚合统计系统运营数据(监控数据)、日志收集等大量数据的数据收集场景。

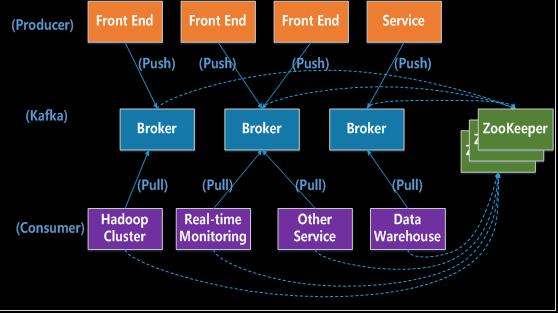
Kafka拓扑结构图一个典型的Kafka集群中包含若干Producer(可以是web前端产生的Page View,或者是服务器日志,系统CPU、Memory等),若干Broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举Leader,以及在Consumer发生变化时进行rebalance。Producer使用push模式将消息发布到Broker,Consumer使用pull模式从Broker订阅并消费消息。
Broker:Kafka集群包含一个或多个服务实例,这些服务实例被称为Broker。
Producer:负责发布消息到Kafka Broker。
Consumer:消息消费者,从Kafka Broker读取消息的客户端。
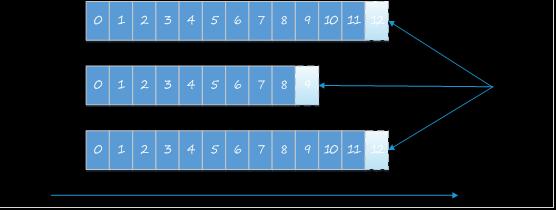
Kafka Topics每条发布到Kafka的消息都有一个类别,这个类别被称为Topic,也可以理解为一个存储消息的队列。例如:天气作为一个Topic,每天的温度消息就可以存储在“天气”这个队列里。
图片中的蓝色框为Kafka的一个Topic,即可以理解为一个队列,每个格子代表一条消息。生产者产生的消息逐条放到Topic的末尾。消费者从左至右顺序读取消息,使用Offset来记录读取的位置。
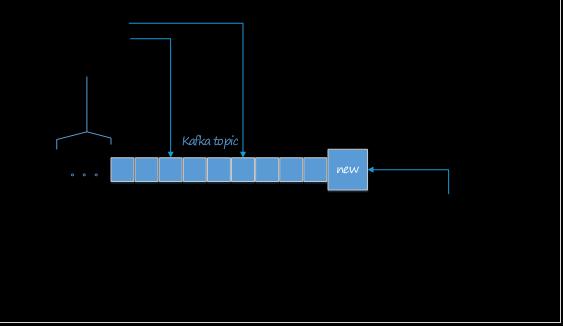
Kafka Partition
每个Topic 都有一个或者多个Partitions构成。每个Partition都是有序且不可变的消息队列。引入Partition机制,保证了Kafka的高吞吐能力。
每个topic被分成多个partition(区),每个partition在存储层面对应一个log文件,log文件中记录了所有的消息数据。
引入Partition机制,保证了Kafka的高吞吐能力,因为Topic的多个Partition分布在不同的Kafka节点上,这样一来多个客户端(Producer和Consumer)就可以并发访问不同的节点对一个Topic进行消息的读写。